
课程介绍
“Applied Analytics(应用分析)”是一门跨学科课程,主要教授如何利用数据分析来解决实际业务或社会问题。它结合了数据科学、统计学、商业分析和信息技术的内容,注重数据驱动决策的实际应用。
学科方向包含:
- 数据分析基础
- 数据收集、清洗与处理
- 探索性数据分析(EDA)
- 数据可视化工具(如 Tableau、Power BI)
- 统计与建模
- 描述性统计与推断统计
- 回归分析、聚类分析
- 机器学习入门(如预测模型、分类模型)
- 数据工具与编程
- Python 或 R 编程
- SQL 数据库操作
- Excel 高级分析
- 商业与战略分析
- KPI 与绩效分析
- 市场细分与客户分析
- 数据驱动的战略决策
- 项目实践(Capstone Project)
- 使用真实数据进行商业案例分析
- 撰写数据报告并提出决策建议
课程目标课程目标(Course Goals)
- 在预测分析(Predictive Analytics)的开发流程中获得实践经验。
- 深入了解医学信息学(Medical Informatics)领域的挑战。
- 理解以下基本概念:
- 数据准备(Data Preparation)
- 描述性与预测性建模(Descriptive & Predictive Modeling)
- 模型评估(Model Evaluation)
- 将所学技能应用于实际问题。
- 能够对预测模型进行批判性评估(Critical Assessment of Predictive Models)。
用途?预测分析(Predictive Analytics)
- 根据历史数据中的模式来预测未来结果。
- 利用统计方法与机器学习算法来建模这些数据模式。
- 在医学信息学中,预测分析被用于提升决策质量与运行效率。
- 在医疗场景中,预测分析可用于:
- 预测患者的再入院风险;
- 提前发现疾病迹象(如糖尿病、心脏病风险模型);
- 优化医院资源分配(如病床或急诊调度);
- 个性化治疗建议(根据历史病例与病人特征)。
预测分析 vs 商业智能 vs 统计学
这些领域都使用相似的数据分析方法,但**目标与关注点不同:
| 角度 | 预测分析 Predictive Analytics |
商业智能 Business Intelligence |
统计学 Statistics |
|---|---|---|---|
| 目标 | 预测未来 Prediction | 描述现状 Description | 验证理论 Inference |
| 方法 | 统计 + 机器学习 | 可视化 + 数据汇总 | 数学建模 + 假设检验 |
| 模型驱动方式 | 数据驱动(Data-driven) | 数据呈现(Data visualization–driven) | 理论驱动(Theory-driven) |
| 数据类型 | 历史数据 + 预测变量 | 历史 + 实时数据 | 实验或抽样数据 |
| 核心问题 | “接下来会怎样?” | “现在是什么情况?” | “为什么会这样?” |
执行步骤
| 阶段 | 关键问题 | 关键词 | |
|---|---|---|---|
| 1️⃣ Business Understanding | 我们要解决什么问题? | Objective | |
| 2️⃣ Data Understanding | 我们有哪些数据? | Structure & Quality | |
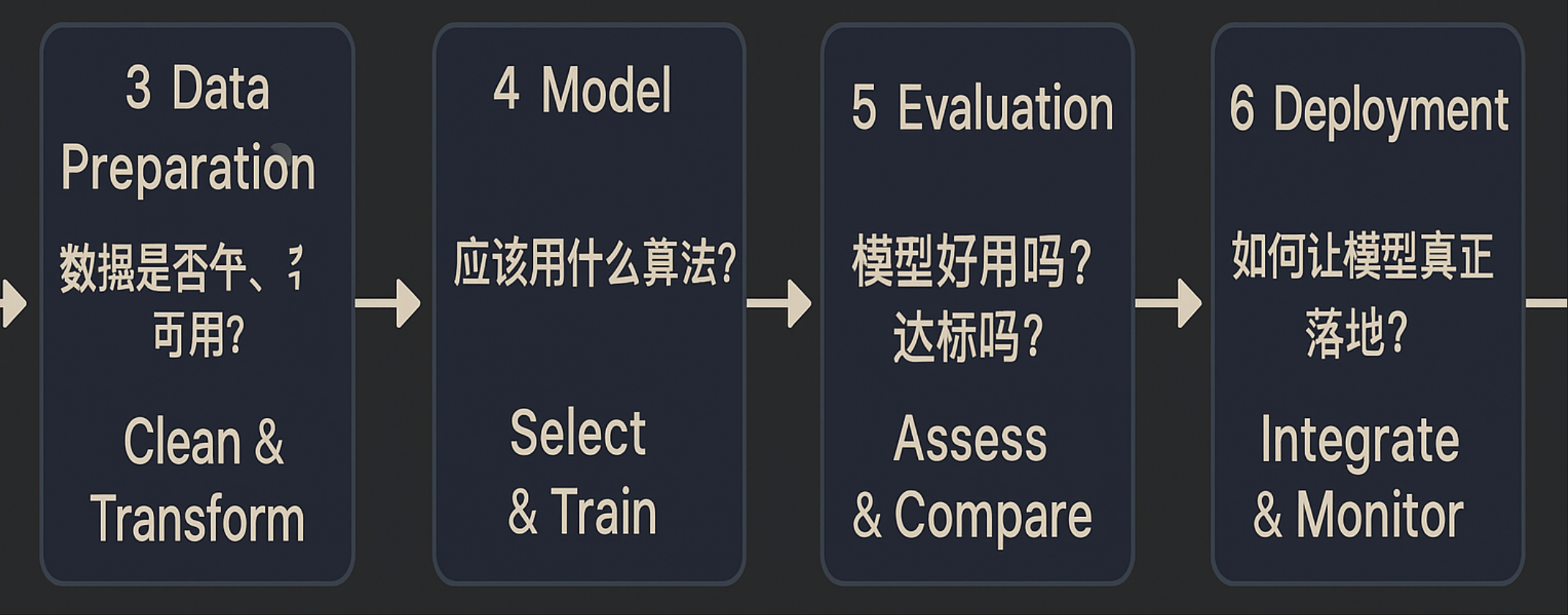
| 3️⃣ Data Preparation | 数据是否干净、可用? | Clean & Transform | |
| 4️⃣ Modeling | 应该用什么算法? | Select & Train | |
| 5️⃣ Evaluation | 模型好用吗?达标吗? | Assess & Compare | |
| 6️⃣ Deployment | 如何让模型真正落地? | Integrate & Monitor |
1、商业理解
确定项目的目标!!!清晰的业务目标,是成功的预测分析项目的起点。
在任何数据分析或预测分析项目中,第一步是理解业务问题(Business Understanding)。
只有明确项目的业务目标与应用场景,后续的数据建模与算法选择才有意义。
- 理解项目的目标与背景
- 对目标进行量化
- 确定可用数据
- 选择合适的建模方法
- 评估模型与业务目标的匹配度
- 考虑模型的落地与应用方式
2、理解数据
探索数据的结构与质量!没有良好的数据理解,就没有可靠的分析结果。
在进入建模前,必须先深入了解数据的基本特征与潜在问题。 这一阶段是整个数据分析流程中最重要的准备步骤之一。
- 检查数据结构(Examine the structure of the data)
- 检查变量的描述性统计(Inspect the descriptives of your variables)
- 可视化数据以获得更深入的洞察(Visualize your data for further insights!)
- 记录分析前需要解决的问题(Note problems that must be addressed before analysis)
3、数据准备
清洗、转换并选择用于分析的数据!将原始数据转化为“可建模的数据”。
在进入建模阶段前,必须确保数据干净、结构合理且符合模型假设。 数据准备阶段通常是整个分析流程中最耗时、但也是最关键的一步。
- 变量清洗与离群值分析(Variable cleaning, outlier analysis)
- 处理缺失值(Address missing values)
- 数据转换(Data transformation)
- 特征/维度缩减(Feature/dimension reduction)
- 数据抽样计划(Plans for data sampling)
- 时间与质量的权衡(Time ↔ Quality trade-off)
4、建模
选择、训练并调优模型!建模阶段不仅是“训练模型”,更是“科学实验”。
在完成数据准备后,进入预测分析的核心阶段:模型构建(Modeling)。 这一阶段的目标是选择合适的算法、训练模型,并通过反复优化提升性能。
- 确定建模技术(Decide which modeling technique(s) you want to apply!)
- 模型训练与测试(Model training and testing)
- 迭代与调优(Iterate with fine-tuning)
- 文档记录以确保可复现性(Document the process for reproducibility!)
5、模型评估
评估并比较模型表现!将模型结果与业务目标相结合!
不仅要判断模型“预测得好不好”, 还要评估它是否真正服务于项目的业务目标。
- 评估模型性能指标(Assess the performance criteria of your model)
- 比较多个模型的表现(If multiple models were trained, compare their performance)
- 解释模型结果(Interprete your model results for additional insights beyond predictions)
- 评估模型的潜在业务影响(Assess potential business impact of your model)
- 检查模型是否满足业务目标(Check if model meets the business objectives)
6、模型部署
将模型部署到真实世界的环境中!Deployment = 从“分析结果”走向“可持续应用”。
实例研究
数据分析让健康 App 推荐从“主观印象”变为“数据驱动的科学决策”。
- 用户 → 找到真正有效、安全的 App;
- 医生 → 基于客观数据做出推荐;
- 开发者 → 了解用户需求,持续优化产品。
通过数据分析与机器学习方法,我们可以系统化地理解用户反馈,并构建透明、可信的健康 App 推荐体系。分析方法与改进作用:
- 情感分析(Sentiment Analysis)
- 文本挖掘(Text Mining)
- 聚类分析(Clustering)
- 预测建模(Predictive Models)
- 推荐系统(Recommendation Systems)
- 促进数据驱动与透明化决策(Data-driven & Transparent Recommendations)
数据集
- Apple App Store :分类(Categories):“Health & Fitness(健康与健身)” 与 “Medical(医学)”
- 其他来源
现状与问题
数据访问受限,数字化创新受到阻碍。
机器学习的发展依赖大量训练数据,但隐私数据受各类限制。
解决方案之一:合成数据
合成数据(Synthetic Data)是指通过模拟真实数据分布、保持统计特征而不含真实个人信息的人工生成数据集。
| 方面 | 优势 |
|---|---|
| 🔒 隐私安全 | 不包含可识别个人的原始记录,规避法律风险。 |
| 🔁 可共享性强 | 多机构可共享,用于算法开发与教学研究。 |
| 🧩 可控性高 | 可在不同场景下生成平衡、无偏的数据样本。 |
| 🧠 模型测试 | 可在不暴露真实数据的前提下进行模型训练与验证。 |
接下来的学习计划
- 数据分析核心方法(Data Analytics Core Methods)
- 大型语言模型(LLMs, Large Language Models)
- 经济分析(Economic Analysis)
提前准备工具:
- Anaconda:Python 的数据科学发行版,核心作用:
- ✅ 集成环境:包含 Python、R、Jupyter Notebook、Spyder 等
- ⚙️ 包管理器 Conda:方便地安装、更新、卸载库
- 🧩 虚拟环境管理:可为不同项目创建独立环境,防止版本冲突
- 💡 稳定性高:适合教学、科研与生产环境使用
- Python:数据分析与建模的核心语言,拥有大量数据分析与AI相关的库,如:
pandas(数据处理)numpy(数值计算)matplotlib / seaborn(可视化)scikit-learn(机器学习)tensorflow / pytorch(深度学习)
- Spyder: 科学计算型 IDE(集成开发环境),可直接编写、运行 Python 代码并查看分析结果。
-
- 🖥️ 左侧代码编辑区 + 右侧控制台 + 下方变量浏览器
- 🔍 可实时查看变量值、数组、图像、数据表
- ⚡ 适合交互式调试与数据探索
- 📊 与
matplotlib、pandas等库无缝整合
-